1. 被选用于检验的感官技术的实质是由具体研究的对象决定的。
2. 熟练的检验小组应请来进行可接受性判断,相反,消费者检验小组不适于进行精确描述检验。
3. 样品标签应随机以3位数编码,以免产生偏见。
4. 样品次序应随机或平衡排列,以避免人为影响。
5. 在评价过程中,专家之间不互相影响干扰。
6. 味觉与嗅觉中的各个混合感官成分在一定范围内会部分地相互抑制,因此,在相同浓度下,一个感官成分在复合产品中所感受到的强度往往比单独品评时低。
7. 连续对嗅觉或味觉的刺激会导致反应降低,成为感官适应。
8. 许多人会混淆味觉和嗅觉,未经训练的检验者会将口中挥发物的嗅觉误认为是味觉。
9. 消费者对口味和香味的反应常常是一种整体的感觉,而训练有素的专业人员则能够进行进一步分析。上述整体感觉在未经训练的受试者被问及某单个属性时会产生糊涂效应(错误或表面印象),因为其他属性的作用使得该属性被夸大了。
10、当检验对象与参照物相似时,一般认为2-3点检验比3点检验更敏感,例如,如果参照物是一个生产历史较长且经过大量现行评估的标准产品,则所检验的相似物的偏差范围比较稳定。
11、当评价小组考察具体属性时,必选检验更敏感,比如成对比较检验。相反,比较总体差别的综合检验(如3点检验)会过低估计差别程度,因为检验样本往往会忽视关键属性。由于进行全面判别检验的话,只要求判断产品间的相对差别而不是比较差别强度,因此,全面判别检验也不如具体属性检验敏感,这是一种顽固的偏见,即只偏重比较差别而不是强度。
12、如果存在疲劳的问题,则可以减少检验样本量。如果不存在疲劳问题,比如当二重标准检验可以完全为评价小组描述样品性质时,则比使用单个参照物的检验(如2-3点检验)或无参照物的检验(如3点检验)敏感度更高。
13、多重检验可通过X2分析检验,对所预期的0、1或2校正选择的概率检验及其观察频率。重复检验可选择用于检验变量且当变量满足要求时可进行组合。
14、评判感官差异的工具的选择取决于其绝对级别:间接衡量,即通过区别检验,能够被用于估计较小差别的感官数值,较大的差别则宜用直接评价法。
15、属性越简单则标度越精确。标度并非划分序列,大多数商品判断的排序(或评分)考虑到许多性质,通常是缺点,并倾向于将它们组合起来而且常常是概括性的。
16、人是很好的感官相对评价“仪器”,而对绝对评价而言则很差。这表明所有标度必须由对照样通过仪器来确定,而这些标样的感官值是可比的。
17、观察者在产品评价过程中会根据参比样的前后关系或组成情况自行调整标准,训练可以避免这一问题,但此时训练能使标度使用的稳定到什么程度还不清楚。大多数前后关系会造成较大的反差,例如,一个好产品与一个稍差的产品相比会显得比原先好得多。
18、感官评价标度通常最好是测量排序,那样就可以给出评分排序,但是要求不出现感官评价值正好在级与级交界的情况。当根据数据获得结论或在参数统计检验后得出统计结论时,记住上述要求是有用的。
19、可以用非标记的检验栏标度来替代数字分类标度以避免数字引起的偏见,在这些标度中、与选择媒介无关,就像在线条标尺上作记号一样的数字或标记,但是这些标度应当给予最终的文字标记,从而对参比样的一般框架设定评价的尺度。
20、类项标度和线性标度对产品判断而言作用基本相同,可能会造成一些过高估计,特别是对消费者的普通群体而言,估计过高对要求灵活性和建立无限制标度的情形(如很强的三叉神经刺激)是有用的,此时,数据往往偏高(包含较高的离群值)。
21、简单、基础性的术语比由许多单个属性组成的复杂术语更精确,对于组合性术语,评价小组将十分艰难地对属性因子进行权衡。这种权衡是造成个体之间差异的来源,从而容易产生误差。
22、评价小组应当对产品种类差别的敏感度以及在实际评价中会遇到的产品属性进行筛选。
23、无论是以文字形式还是由参比样标准得到的物理形式的术语,都应对评价小组定义清楚。
24、在重点评价实施之前,检验小组应当获得一致意见(并通过统计方法检验),小组的共同意见关系到术语的定义以及用于强度判断的参比样的框架。
25、描述标度的最终定位必须是感官可行的,例如,如果一些产品完全没有某种属性则应在级别低的一段注明“全无”。
26、描述分析必须通过重复样品来进行,以提供统计强度和检验评价小组行为的个体差异。
27、一般用术语“可接受”和“可接受性”来表示喜欢与讨厌的程度,如同用典型的数字标度评估一样。“偏爱”从另一方面而言是指在产品中进行挑选,而“排序”是用多重样品进行偏爱检验的形式,排序并不表示评估。
28、偏爱检验比可接受性分级更敏感,这是普遍承认的,然而,证实这一观点较为困难。此外,由于两种产品可能都不被喜欢(偏爱则在这两者之间还能选出较好的),因此,可接受性实验数据所包含的信息更丰富,而且偏爱检验本身常常根据可接受性分级实验得出结论。
29、对称的9点快感标度很有效、灵敏,且是衡量可接受性的良好评价工具。
30、作出无偏爱的选择很难满意地操作且难以满足普遍的要求,如果必须作出选择的话,在作出无偏爱的结论同时往往附有一个在一定范围内的偏爱。
31、消费者可接受性检验的对象应是所研究产品的真实消费者,观察项目为使用频率。
32、为了避免受试者问到一些没有考虑过的属性而产生偏见,应首先询问一些总体意见的问题,然后再针对具体属性进行调查,其程序是由概括性问题到具体问题。
33、调查时应询问受试者比较了解的问题(他们会知无不言),要保持提问的简单与直接。
34、采用无限制性问题时应注意其局限性:这类问题有利于言语表达自由的、反应性强的评价小组,但在编码的转译与总结方面受到限制。
35、限制性选择题(限定选择项)应包括相互排斥与补充的对象。
36、对受试者进行预测验是必要的。
37、家庭检验是消费者测试方法中最实用与最易实施的,但也最易受干扰、最昂贵及最不可靠,相反的是对中心地区居民进行测试,把其受试者当做“消费模特”(具有较高的可控性、可信度,而代表性较差)。
38、感官测试应缩小概念方面的问题,只要给予一定的概念性信息以保证产品使用正确以及表达正确的分类就足够了。如果想获得参比样的进一步内容如组成成分,则须由消费者进行概念化产品测试。
39、不要指望无标签感官测试与概念化产品市场调查检验的结果相同,它们各自目的不同,没有绝对的对与错。
40、集中小组面试对产品开发及其后期工作是有益的,例如,它们可用于创造术语(在描述和消费者使用中)、设计调查问卷以及后续的家庭测试中开展新的或未确定的项目。
41、对于偏高的数据或含较高离群值的数据,中间值或几何平均值中间趋势的适宜度量,但不是指算术平均值。对两边分布型的数据,均值的代表性也较差,这些数据应当用图描述或表示。
42、无论何种场合,应使用有自身质量对照样的对象,这意味着具有完整的设计(包含项目分析)。成对t检验几乎总比组间(独立t)检验灵敏,应为一个项目的判断通常需要相互校正,上述原则的平行样数量范围要求一个完整的块设计(如在方差分析的重复测定中,所有评价小组成员评价所有的产品)比包含评价不同产品进行组间比较的替换设计更灵敏。
43、在这些设计中,包含的评价小组成员之间的差异能够容易地从整体误差中分离开来,从而提高检验的敏感性。
44、评价小组成员的影响中一般不考虑其训练度的影响,因为其不反映随目的而变化的任何特定属性的选取水平。因而正确的方差分析的误差术语取决于评价小组成员因素的相互作用。
45、单侧检验适用于判别和对差别分级,双侧检验几乎适于其他所有检验,包括偏爱检验。
46、基准、空白或对照样检验在某些设计中至关重要,它们在下列检验中采用以下形式:
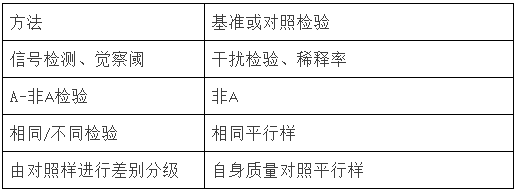
47、在下列情形时,应由仪器替代人工判断:
(1)校正曲线已建立。
(2)重复、疲劳或危险的评价工作。
(3)从商业角度看数据结论不是至关重要的。
48、校正只在产品检验范围内具有良好线性,因此,即使产品不工业化生产或销售,极限值也必须包括在设计中,不具备清楚界限的较宽范围就不能很好估计属性的功能。
49、校正只在所用方法误差置信范围内具有良好线性,因此,良好的感官技术才能获得相关性良好的仪器数据,相反,较差的或有缺陷的技术会妨碍良好仪器相关性的获得。
来源:感官科学与评定,转载请注明来源。
参考文献:《食品感官评价原理与技术》(美)拉夫莱斯等著,王栋等译. 北京:中国轻工业出版社,2001.6


